tl;dr: I tried out a modified Python lesson and I think it was successful at balancing learner motivation with teaching foundational (and sometimes boring) concepts.
In many ways, teaching Python to scientists is easier than just about every other audience. The learning objective is clear: write code to make my science more accurate, more efficient, and more impactful. The motivation is apparent: data is increasingly plentiful and increasingly complex. The learners are both engaged and prepared to put in the effort required to develop new skills.
But, despite all of the advantages, teaching anybody to program is hard.
In my experience, one of the most challenging trade-offs for lesson planners
is between motivating the material and teaching a mental model
for code execution.
For example, scientists are easily motivated by simple data munging and
plotting using pandas and matplotlib;
these are features of the Python ecosystem that can convince a graduate
student to pay attention to the material instead of answering emails.
Actually using these features, however, requires a long list of basic
concepts: Python syntax, libraries, function calls, objects and methods,
conditionals, and variable assignment, to name just a few.
A lesson planner can start from the basics, working in to these features along the branches of the dependency tree, but that could require hours (or even days) of "boring programming". It's all too easy to dismiss learners who lose interest before you get to the good stuff, but it is more a reflection of the materials and instructor, than the students.
At the other extreme, a lesson could start with working code, or, in the Software Carpentry style the instructor could lead learners through writing code that uses these features, before the concepts have been fully introduced. This in-at-the-deep-end approach quickly demonstrates exciting uses of Python, but at the risk of intimidating learners, making them wonder if they're the only one in the room who's confused by what's going on under the hood and what all of the syntax means. I'm not aware of any studies on this topic (if you are, please pass them my way), but I'm willing to speculate that this second approach has a higher risk of subjecting learners from underrepresented groups to stereotype threat, a major risk when teaching a subject with a pervasive diversity problem.
Luckily for us all, there's a whole spectrum of approaches in between the motivations-first and foundations-first extremes. We can trust learners to self-motivate for a time, especially when we're teaching scientists. Attendees are there voluntarily (I would hope). Likewise, learners will never have a perfect understanding of how their code is working, regardless of how long you spend teaching the basics. The key is to avoid unintentionally teaching pathological mental models that are difficult for the instructor to diagnose and iterate beyond.
State of the Python lesson
As of this writing, the current default Python lesson for Software Carpentry is "Novice Inflammation"1. I have written previously about my experience with the lesson, and have not been shy with my criticism. There is a lot to be positive about in the composition of Inflammation. It has been an effective approach to teaching Python to what at this point must be several thousand workshop attendees.
However, this post is about how we can do better. My primary criticism focuses on the first section: "Analyzing Patient Data". The approach here falls towards the motivation-first extreme. Learners are shown how one might go from raw data in a CSV to heatmaps and line plots, two useful skills.
The downside, however, is that this happens without fully explaining the
syntax, what libraries are, numpy arrays versus Python lists, dtypes vs
built-in Python types, and more.
I think that by using this particular motivating example while glossing over
those details we're giving learners a challenging mental model to iterate
beyond.
What's more, I believe that this results in a diversity of models
making later instruction more likely to leave some learners behind.
Novice Inflammation also gets stuck in the weeds over difficult concepts which,
in my opinion, aren't nearly as important for learners, for example,
accumulating over particular axes in numpy arrays.
For this and other reasons Greg Wilson spearheaded an attempt to reinvent the Python lesson. The "Novice Gapminder" lesson2 is a from-scratch re-write. It's worth noting that SWC's normal pull-request model for lesson development is unable to accommodate a major overhaul like this one.
Gapminder is different in several ways, for instance using pandas as a focal
library instead of numpy.
Notably for this commentary, though, it also takes a much more gradual approach
to motivating the material.
pandas and matplotlib are not introduced until the end of the first
half-day,
and only after a thorough discussion of variable assignment, functions, and
data types.
The Gapminder lesson also appears to lack the distractions and rabbit holes
that I've criticized in Inflammation.
Overall, I think Gapminder hits a superior balance between motivation and basics, while also improve the structure and refining the details. I have to applaud everyone who's contributed to its development. I've now taught from the new lesson once, and co-instructed a workshop that used the first half. The improvements in the design were apparent both times. I expect it to be well received by the SWC community when it becomes the default.
Continual improvement
That's not to say, however, that it cannot be improved.
The same motivation-vs-foundations question has already come up in
a discussion on GitHub.
A proposal was made to delay the use of pandas and matplotlib until the
second half, further front-loading the basics.
My personal opinion, having taught the lesson is that
this is unnecessary.
With the Gapminder lesson, by the time we got to these more advanced topics at
the end of the first half-day, learners appeared to be ready for the material,
comfortably updating their mental models in an appropriate way.
And, thankfully, I also didn't notice a loss of engagement due to the delayed
pay-off.
Like many trade-offs in lesson design, the optimal position on the motivations/foundations spectrum is context dependent. I would focus on cool application instead of basic concepts for the first session if I were teaching high school students or any learners skeptical about the utility of the material. A room full of scientists who were there specifically to learn Python, however, could probably tolerate even more front-loading of syntax and control-flow. A framework to help instructors customize the materials for their audience would be a very useful addition.
The main purpose of this post is to nominate a slightly different approach which introduces an advanced example early in the lesson without the risk (I believe) of intimidating learners.
In December 2016 I co-instructed a (not officially SWC) workshop which taught Python over two half-day sessions to about 20 learners, primarily graduate students in the biological sciences.
My co-instructor, Jackie Cohen (\@jczetta), taught the first half-day using the Gapminder lesson. The positive reception from learners to the first half of the material was testament not only to her skillful instruction, but also the quality of the design.
I then taught the second day with the same gapminder dataset and covering the same topics as the normal materials, but using a custom lesson plan. Inspired by a comment on the Gapminder GitHub repository, I constructed a "realistic" analysis of the gapminder data as a Jupyter notebook. In particular, the notebook includes code to generate a fairly involved figure telling a story about the relationship between per-capita GDP and life-expectancy.
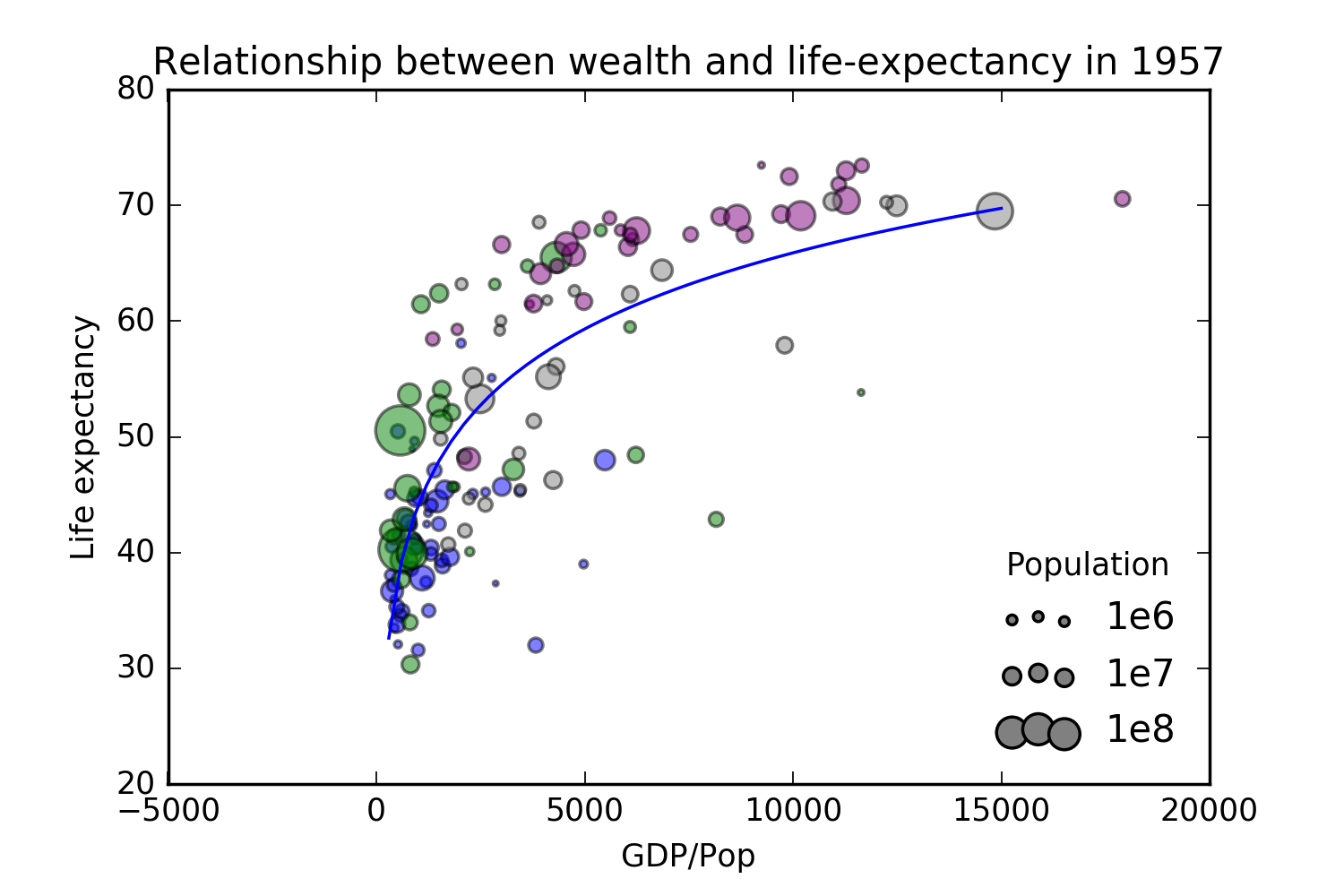
I started the second day by having learners download and run this notebook, demonstrating the quality of analyses they could produce with fewer than 100 lines of code. By not live-coding, and not expecting the learners to type along during the introduction, I believe this approach minimizes the likelihood of intimidating the learners with syntax. To that end, I also did not walk through the code itself, but instead focused on describing the overarching flow of the analysis: loading external data, selecting a subset, plotting two columns as a scatter-plot with a third column determining the size of the points, running a linear regression, and plotting a best-fit line. The purpose of this introduction was purely to motivate the material, not to introduce the concepts.
I then had them open a new, empty notebook, and the remainder of the lesson (which was done in the traditional live-coding style) then revolved around reconstructing the same analysis from scratch, a thematic unification, that I found to be elegant. Since the pre-constructed analysis made use of for-loops, if-statements, and functions, I was able to limit my use of foo/bar style examples and quickly return to the core analysis demonstrating the use of these elements in a realistic setting. Our workshop was advertised as an introduction to Jupyter notebooks, data manipulation, and plotting, (as well as novice Python) so a significant fraction of the time was spent on these topics and libraries instead of more foundational concepts.
Where to go from here?
I found this approach to be quite successful. In-person and exit survey feedback has been uniformly positive and learners appeared to have achieved most or all of the learning objectives of the core Gapminder lesson. While the "realistic analysis" approach sounds more like the Data Carpentry style, in this particular case it was a great fit for the Software Carpentry learning objectives.
I believe that this model could be implemented in the core Gapminder lesson, perhaps starting in the second half (as we did), or with a different example notebook for each half-day. That would, however, entail modifying most or all of the sections to focus on the new unified example. Is it worth expending the tens of hours required to implement it? Even if it were implemented, I'm not convinced that the SWC lesson development model makes this kind of large-scale refactoring feasible.
As an alternative to submitting a pull request, I'm hoping that I can convince a few instructors to try it out for themselves. Positive experiences with an unofficial fork makes patching the main branch a more rational investment. I've already been evangelizing in a similar way for an alternative Git lesson, sharing my immature outline and encouraging folks to try it out themselves. Is there a better approach to making medium to large changes to the design of a SWC lesson?
In conclusion: I think we need additional discussion (and data) about the motivations/foundations trade-off in our lessons. I'd also like to hear your thoughts on the best way to lobby for and introduce moderately sized changes to the core materials. What do you think about my approach? If you're feeling brave, please try it out and let me know how it goes!
-
HEAD at 030f3fbd30 ↩
-
HEAD at e303e6a9d3 ↩
Comments